Google is a search engine that follows links. For Google to know about your site, it has to find it by following a link from another site. When Google cames around to crawl any other site after we put the link there, it can discover the existence of my other, new site. And Google indexes it.
Googlebot: The One-and-Only Guide On How to Control and Observe It
Almost everyone in this digital world knows about the Googlebot, but the novice content manager or starter website business will have some sort of doubts. So for them, and for everyone else, the basic guide for Googlebot is quite useful.
Question 1: What is Googlebot?
Simply put, Googlebot is a ‘WebCrawler’ used by Google and Google Search Engine. ‘Web Crawlers’ are also well known as spiders, or robots.
Web Crawlers or Robots ‘crawl’ or ‘catch’ the required informations from around the web and in structural language arrange them as search results. Commonly, Googlebot or Web Crawler or Robot or Spider, is defined as Search Bot Software.
Google Bot, for example, crawls trillions of websites and webpage’s consistent and throughout the entire world wide web. Google makes use of GoogleBot to search and scan the web sites and retrieve information from them.
Question 2: What Does Googlebot Do?
Googlebot primarily checks the data on the web. Then it moves to the web page. It scans the complete information present in your webpage’s, its structure, layout, contents, files.
Then it retrieves the data it has scanned. Thereafter, it follows your pages/posts and checks every link that you have mentioned with any published and publicly available content. It scans everything including text files, code, image alt tags etc. Then it provides the scanned information to Google for indexing your site. This is all about Google Bot and what does Googlebot do.
But, what is Google Index?

Question 3: What is Google Index?
Google index is just like a library which stores every webpage’s in it.
When every Googlebot collects new information from your website and provides those to Google index, google index updates the content regarding your blog in it and then the page is indexed simultaneously. Google Index receives the information from the Google Bot and stores the information.
But what does Google Index it do after storing the data?
Google Index ranks your page or site or website. That means it provides a source to discover your website in the Google (or any other: Bing, Yahoo, Yandex etc) Search Engine. So, if you want to make you site visible, your site must be indexed. Hence, Googlebot should crawl it.

Question 4: How Does Googlebot see a Webpage?
Firstly google bot doesn’t go through the web page as we humans do. Bots only see the individual part of the page like HTML, CSS, JS, image etc.
While checking through a web page, if the Bot finds anything inaccessible then it just ignores them and it does not collect any information from that particular page. Googlebot can’t even access a page if you have blocked any CSS or JavaScript coding using the robots.txt file.
So if Googlebot doesn’t gather any information from your web page, then it can’t be indexed. Hence, you won’t be visible in the Google Search Engine. So make sure whether you have submitted or made a way for Google Bot to crawl your page.
Inspection: Common Problem Where Googlebot Can’t Index
These are some of the common problems where Googlebot can’t be indexed.
- When blocked by robots.txt file.
- Image link and alt link.
- If modified since HTTP header.
- If page links are not readable or correct.
- Overwhelming on flash or other technologies that web crawlers may have
- An issue with Bad HTML or coding errors.
- Over complicated dynamic links.
So now we are acquainted with Google Bot. We have learned the benefits of Google Bot crawling and indexing. But have we thought to hide our private content or web page information which we don’t want to share? So definitely, we should have a control over Google Bot. Then here it is.
Question 5: How can we control a Google Bot?
Googlebot is commonly controlled by using the robots.txt file.
Googlebot follows the instruction received from robots.txt. Well, the robots.txt file is a set of instructions provided to Google Bot whether to scan or access the particular page or the particular content of the page. By using the robots.txt file, we can control Googlebot. Apart from these, there are other measures to control.
We can control Googlebot by:
- Using sitemap.
- Making use of google search console.
- Placing robot’s instruction in the header.
- Providing robot’s instruction in the metadata of the web page.
These are the measures to control Googlebot.
Question 6: How to check whether our page is perfectly indexed?
If we want to check whether our web page is indexed or not, then follow this tip.
Just type, in Google Search address bar: Site: Your site name i.e. site:yourwebsite.com
Now, by typing these, you are asking Google to show all the indexed web pages.
Example: whoops.online
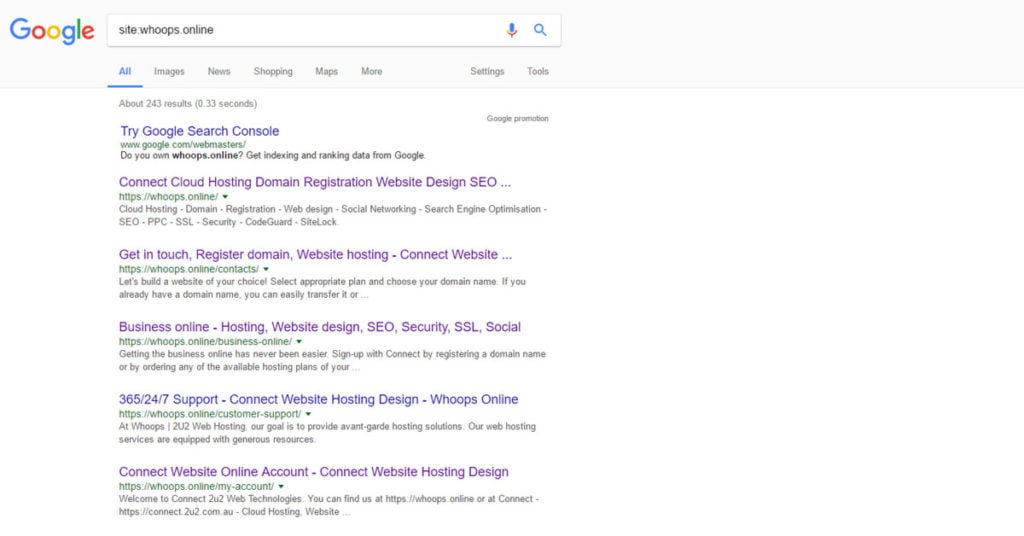
If you are not able to find any webpage’s, it means your pages are not indexed yet. So be wiser and cautious when you control Googlebot.
I hope this article has helped you regarding Google and Website Indexing. Thank you for reading! If you need any support, Contact us, or, if you wish Professional support, order SEO Audit.
[wpseo_map width=”100%” height=”300″ zoom=”-1″ map_style=”roadmap” scrollable=”0″ draggable=”1″ show_route=”0″ show_state=”1″ show_url=”0″] [wpseo_address hide_address=”1″ show_state=”1″ show_country=”1″ show_phone=”1″ show_phone_2=”0″ show_fax=”0″ show_email=”1″ show_url=”1″ show_logo=”0″ show_opening_hours=”1″]
6.
Googlebot: The One-and-Only Guide On How to Control and Observe It
Related Articles


